Role & Tech Stack
나의 역할: Prometheus/Grafana 기반 모니터링 시스템 설계·구축, 오토스케일링 관측 파이프라인 구현
기술 스택: Kubernetes, Prometheus, Grafana, RabbitMQ, FastAPI, React, Docker
1. 기획 배경
해결하고자 한 문제: AI 간 대전을 지원하는 플랫폼은 순간 피크 트래픽과 AI 추론 지연으로 가용성과 사용자 경험이 쉽게 악화됩니다. 전통적인 모놀리식 구조는 서비스 간 결합도가 높아 장애 전파 위험과 확장 한계가 컸습니다.
타겟 사용자: AI 모델을 업로드하고 다양한 보드게임에서 대전 결과를 확인하고 싶은 사용자 및 연구·교육 목적의 AI 성능 비교 플랫폼 운영자
프로젝트 목표: MSA와 Kubernetes 기반 컨테이너 오케스트레이션을 통해 게임 서버, AI 추론 서버, API 게이트웨이, 메시지 브로커를 느슨히 결합한 고신뢰·고확장 분산 게임 서버 시스템을 구현하는 것이었습니다.
2. 핵심 성과
- 사전 모니터링 파이프라인 구축: 복잡한 게임·AI 로직 구현 전 Mock-up 서버 환경에서 Gateway–AI–Game 아키텍처와 Prometheus/Grafana 통합 파이프라인을 선행 검증했습니다.
- 오토스케일링 환경에서 무설정 자동 감지: Pod를 3대에서 5대로 증설하는 시나리오에서 별도 설정 변경 없이 Prometheus PodMonitor가 신규 Pod를 자동 감지하고 Grafana 그래프를 분리 표출함을 검증했습니다.
- 4개 계층 통합 대시보드 구성: Gateway, AI Server, Game Server, RabbitMQ의 핵심 지표를 단일 Grafana 대시보드에서 통합 관제하도록 구성했습니다.
3. 기술 스택 및 도입 배경
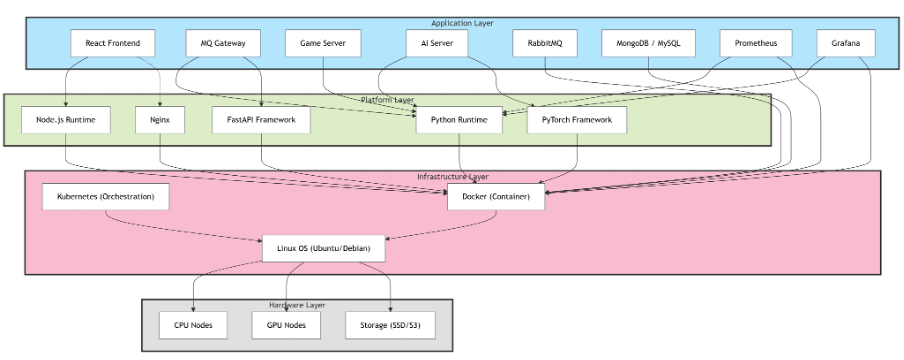
Why Prometheus Operator? 분산 MSA 환경에서는 Pod가 동적으로 생성·삭제되므로 정적 설정 방식으로는 모니터링 대상을 추적하기 어렵습니다. ServiceMonitor·PodMonitor CRD를 통해 타겟을 선언적으로 정의하면 스케일아웃 상황에서도 누락 없는 메트릭 수집이 가능합니다.
Why RabbitMQ? AI 추론 지연으로 인한 턴 진행 적체 문제를 해결하기 위해 Pub/Sub 구조의 메시지 브로커를 도입했습니다.
Why Kubernetes + HPA/KEDA? AI 추론 부하는 시점별로 급격히 변하므로, AI Server를 독립 마이크로서비스로 분리하고 자동 확장을 적용해 피크 상황에 대응하도록 설계했습니다.
4. 나의 핵심 기여
- Mock-up 서버를 활용해 Kubernetes 위에 Prometheus Operator·Grafana 파이프라인을 선행 구축
- 접속자 수, 추론 속도, 게임 매칭, 큐 적체 등 실제 패턴을 모사하는 더미 데이터 기반 대시보드 검증
- Prometheus CRD(PodMonitor)를 통해 동적으로 생성되는 Pod를 별도 설정 없이 자동 스크랩하는 구조 설계
- Gateway, AI Server, Game Server, RabbitMQ 4개 서비스의 핵심 지표를 계층적으로 구성한 통합 대시보드 구축
4.5. 구현 결과
Grafana 통합 대시보드

- Gateway: 실시간 활성 사용자 및 초당 요청 수 추이 확인
- AI Server: GPU 추론 지연 시간 및 파드별 부하 분산 현황
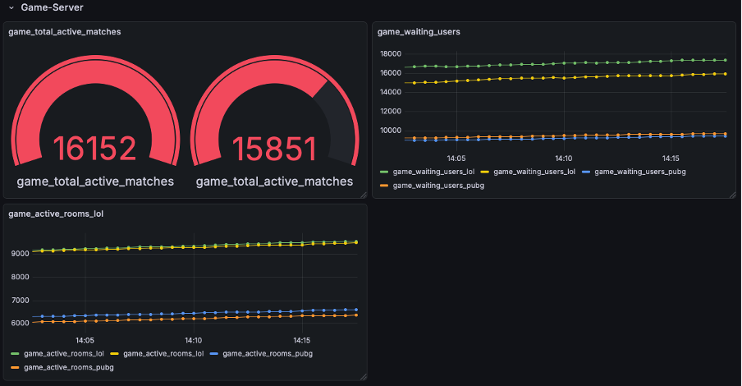
- Game Server: 게임 종목별 실시간 매칭 및 대기열 현황
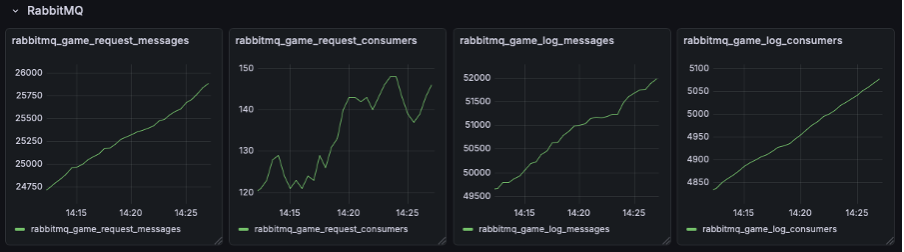
- Infra(RabbitMQ): 실제 브로커 연동 전, 가상의 큐 적체 시나리오를 구현하여 대시보드 표출 및 알람 파이프라인을 선행 검증
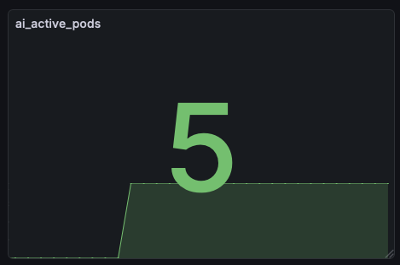
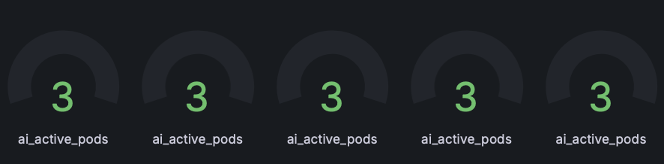
- 테스트 시나리오: AI 트래픽 증가를 가정하여 추론 서버 Pod를 3대에서 5대로 강제 증설
- 결과: 별도 모니터링 설정 변경 없이 5개의 Pod 데이터를 자동 감지하고 그래프를 분리하여 표출
게임 화면
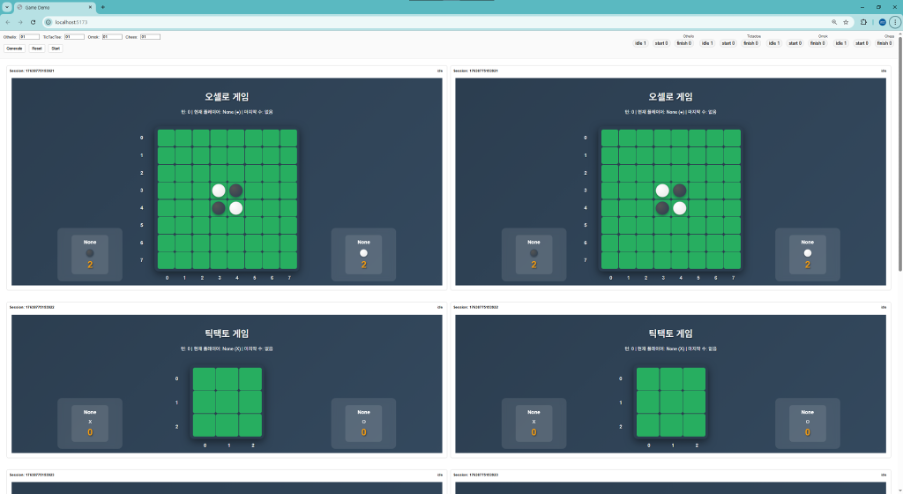
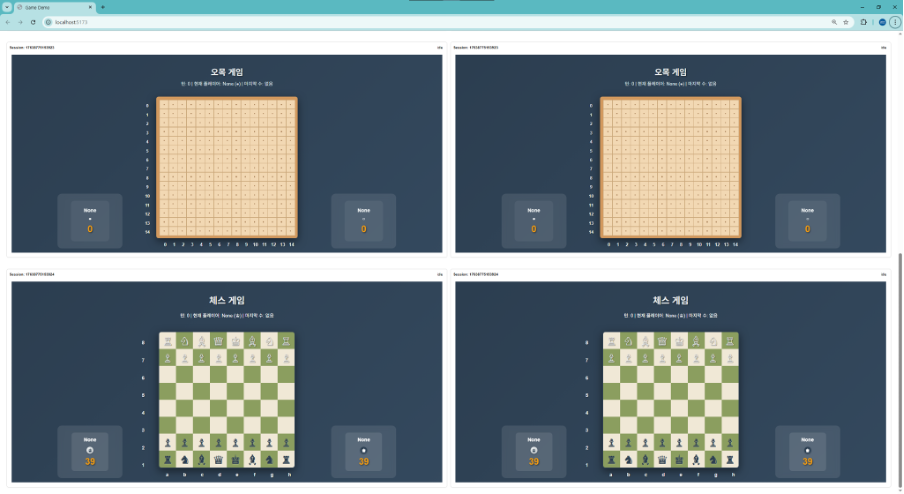
- 다수의 세션이 동시에 독립적으로 진행되는 것을 확인할 수 있습니다.
- 오셀로, 틱택토, 오목, 체스 4종의 게임이 각각 별도 세션으로 생성되며 AI 추론 결과를 실시간으로 수신해 보드 상태를 갱신합니다.
- 우측 상단 대시보드에서 각 세션의 상태를 실시간으로 확인할 수 있습니다.
5. 기술적 문제 해결
동적 Pod 환경에서 모니터링 사각지대 발생
HPA로 Pod가 자동 증설될 때 신규 Pod가 모니터링 대상에 포함되지 않는 문제가 생길 수 있었습니다. PodMonitor CRD를 도입해 라벨 셀렉터 기반으로 타겟을 선언적으로 정의했고, 3대에서 5대로 증설되는 시나리오에서 자동 수집을 검증했습니다.
RabbitMQ 큐 적체 알람 파이프라인 선행 검증
실제 브로커 연동 전에는 큐 적체 시나리오를 재현하기 어려웠습니다. 메시지 큐 적체와 트래픽 흐름을 모사하는 시뮬레이터를 개발해 Prometheus에 가상 메트릭을 주입하고 Grafana 대시보드 표출과 알람 파이프라인을 검증했습니다.
6. 프로젝트 회고
분산 시스템에서 관측 가능성은 기능 구현만큼 중요한 1급 요건이라는 점을 체감했습니다. 특히 동적으로 변하는 Pod 환경에서 선언적 모니터링 구성과 Mock-up 기반 사전 검증이 개발 리스크를 줄일 수 있음을 경험했습니다.